class: center, middle <br/> # Bayesian Methods for Machine Learning .small-vspace[ ] ### Lecture 7 - Deep generative models <br/><br/> .bold[Simon Leglaive] <br/> <br/> <br/><br/> .tiny[CentraleSupélec] --- class: center, middle count: false # Neural networks in 5 minutes --- ## Artificial neuron .left-column[ $$\hat{y} = f(\mathbf{x}; \theta) = \sigma\left(\mathbf{w}^T \mathbf{x} + b \right) = \sigma\left(\sum\_i w\_i x\_i + b\right),$$ where - $\mathbf{x}$ is the input vector; - $\hat{y}$ the scalar output; - $\mathbf{w}$ is the weight vector; - $b$ is the scalar bias; - $\sigma$ is a non-linear activation function; - $\theta = \\{\mathbf{w}, b \\}$ are the neuron's parameters. ] .right-column[ .right.width-60.center[  ] ] .reset-column[] --- ## Layer Neurons can be composed in parallel to form a .bold[layer] with multiple outputs: .left-column[ $$\hat{\mathbf{y}} = f(\mathbf{x}; \theta) = \sigma\left(\mathbf{W}^T \mathbf{x} + \mathbf{b} \right),$$ where we have now - an **element-wise** activation function, - an **output vector** $\hat{\mathbf{y}}$, - a **weight matrix** $\mathbf{W}$, - a **bias vector** $\mathbf{b}$, - such that $\theta = \\{\mathbf{W}, \mathbf{b} \\}$. ] .right-column[ .right.width-60.center[ 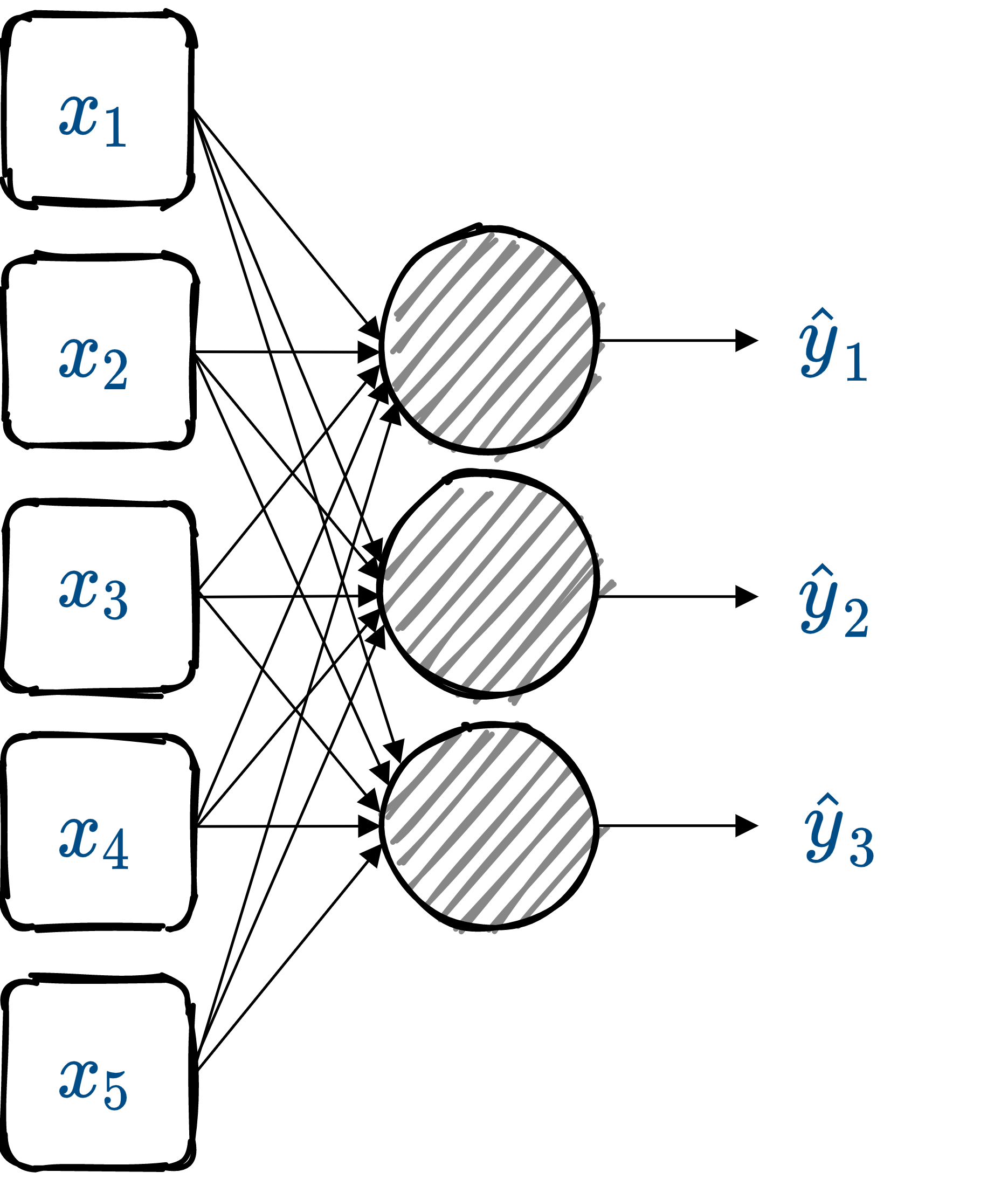 ] ] --- ## Multi-layer Perceptron Similarly, layers can be composed in **series**, to form a **multi-layer Perceptron**, or **feed-forward fully-connected** neural network. .width-50.center[  ] The model parameters are the weight matrices and bias vectors of all layers. --- ## Supervised learning - **Training dataset** (step 0): $\mathcal{D} = \\{\mathbf{x}\_i, \mathbf{y}\_i\\}_{i=1}^N$ where the $\mathbf{x}_i$'s are the inputs, and $\mathbf{y}_i$'s the labels. - **Model** (step 1): A neural network $f(\cdot; \theta)$. - **Loss function** (step 2): $$\mathcal{L}(\theta) = \frac{1}{N} \sum\_{(\mathbf{x}\_i, \mathbf{y}\_i) \in \mathcal{D}} \ell\Big(\mathbf{y}\_i, f(\mathbf{x}\_i; \theta)\Big),$$ where $\ell(\cdot, \cdot)$ is task-dependent. - **Training** (step 3): Minimize $\mathcal{L}(\theta)$ with (variants of) gradient descent and backpropagation. - **Evaluation** (step 4): Test the performance on examples that were not seen during training. --- class: center, middle count: false # Introduction --- exclude: true class: middle ## Supervised learning .center[The majority of successful applications of machine/deep learning rely on **supervised learning**.] .grid[ .kol-2-3[ .center[ <iframe width="600" height="310" src="https://www.youtube.com/embed/qWl9idsCuLQ?start=10&mute=1&loop=1&autoplay=1&playlist=qWl9idsCuLQ" frameborder="0" allow="autoplay; encrypted-media" style="max-width:100%" allowfullscreen=""></iframe> ] .center.tiny[Semantic urban image segmentation with ICNet (Zhao et al., 2018)] ] .kol-1-3[ .medium[ The Cityscapes dataset <br>.tiny[(Cordts et al., 2016)] - **5k images** with high quality pixel-level annotations - **1.5h** to annotate each single image .alert-90[More than 300 days of annotation! 😱] ] ] ] .alert[It is intractable to collect labels for every scenario and task.] <br> .credit[ M. Cordts et al., The Cityscapes dataset for semantic urban scene understanding, IEEE CVPR 2016 <br> Zhao et al., ICNet for real-time semantic segmentation on high-resolution images, ECCV 2018 ] --- exclude: true ## Unsupervised learning .center[We need **unsupervised** methods that can learn to unveil the **underlying structure** of the data without or with few ground-truth labels.] .center.width-70[] .tiny.center[GENESIS (Engelcke et al., 2020), a generative model of 3D scenes capable of both decomposing and generating scenes by capturing relationships between scene components. Image credits: (Engelcke et al., 2020).] .alert[Deep generative models have emerged as promising approaches.] .credit[ M. Engelcke et al., GENESIS: Generative scene inference and sampling with object-centric latent representations, ICLR 2020. ] ??? - GENESIS pursues a consistent strategy for scene generation: Step one generates the floor and the sky, defining the layout of the scene. Steps two to four generate individual foreground objects. Some of these slots remain empty if less than three objects are present in the scene. The final three steps generate the walls in the background. - Unsupervised models can also be used for **semi-supervised learning**, where the goal is to exploit both a **small-scale labeled** dataset and a **large-scale unlabeled** dataset. The unlabeled data are used to learn a representation that makes the supervised task simpler. The resulting semi-supervised model performs typically better than a supervised model trained on the small labeled dataset. --- ## Generative modeling .small-vspace.center.width-50[] The goal is to tune the parameters $\theta$ of the model distribution $p(\mathbf{x} ; \theta)$ so that it is as close as possible to the true data distribution $p^\star(\mathbf{x})$, according to some measure of fit. For instance, minimizing the Kullback-Leibler (KL) divergence $D\_{\text{KL}} (p^\star(\mathbf{x}) \parallel p(\mathbf{x}; \theta))$ is equivalent to maximum likelihood estimation. --- ## 1-dimensional toy example - We define the true data distribution $p^\star(x)$ as a Gaussian distribution with known mean and variance, but of course usually we do not know this distribution. - We assume a Gaussian model distribution $p(x ; \theta) = \mathcal{N}(x; \mu, \sigma^2) $ where $\theta = \\{ \mu, \sigma^2 \\}$. - The parameters $\theta$ are estimated by minimizing .tiny[(a Monte Carlo estimate of)] $D\_{\text{KL}}\left( p^\star(x) \parallel p(x; \theta) \right)$, i.e. by maximum likelihood. .center.width-50[] --- ## $10^6$-dimensional example .vspace[ ] <div style="text-align:center;margin-bottom:30px"> <iframe width="700" height="400" src="https://www.youtube.com/embed/6E1_dgYlifc?autoplay=1&mute=1" frameborder="0" allow="autoplay; encrypted-media" style="max-width:100%" allowfullscreen=""></iframe> </div> .credit[T. Karras et al., [Analyzing and Improving the Image Quality of StyleGAN](https://arxiv.org/abs/1912.04958), CVPR 2020.] --- ## Deep generative models (DGM) - The model distribution $p(\mathbf{x} ; \theta)$ is somehow defined by means of a neural network. - Two seminal DGMs with **low-dimensional latent variables** introduced in 2014: - Variational autoencoders (VAEs) .tiny[(Kingma and Welling, 2014; Rezende et al., 2014)] - Generative adversarial networks (GANs) .tiny[(Goodfellow et al., 2014)]. - DGMs contain millions of parameters and can be trained in a scalable way using large datasets of unlabeled high-dimensional data. .center.width-60[] .credit[ I. Goodfellow et al., "[Generative Adversarial Networks](https://arxiv.org/abs/1406.2661)", NeurIPS 2014.<br> D.P. Kingma and M. Welling, "[Auto-Encoding Variational Bayes](https://arxiv.org/pdf/1312.6114.pdf)", ICLR 2014.<br> D.J. Rezende et. al, "[ Stochastic backpropagation and approximate inference in deep generative models](https://arxiv.org/pdf/1401.4082.pdf)", ICML 2014. ] --- .center.width-100[] .credit[Image modified from https://cvpr2022-tutorial-diffusion-models.github.io/] --- exclude: true ## Several flavors of DGMs **Autoregressive DGMs** define the model distribution recursively, using the chain rule: $$ p(\mathbf{x} ; \theta) = p(x\_1) \prod\_{i=2}^D p(x\_i \mid x\_{1:i-1}; \theta). $$ .vspace.center.width-50[] .credit[ A. van den Oord et al., [WaveNet: A generative model for raw audio](https://arxiv.org/pdf/1609.03499.pdf), arxiv preprint, 2016. Image credits: https://deepmind.com/blog/article/wavenet-generative-model-raw-audio ] --- exclude: true **Flow-based DGMs** transform a simple distribution into a complex one by applying a sequence of invertible mappings: $$ \mathbf{x} = f\_K \circ ... \circ f\_1(\mathbf{z}\_0), \qquad \mathbf{z}\_0 \sim p_0(\mathbf{z}\_0). $$ .center.width-70[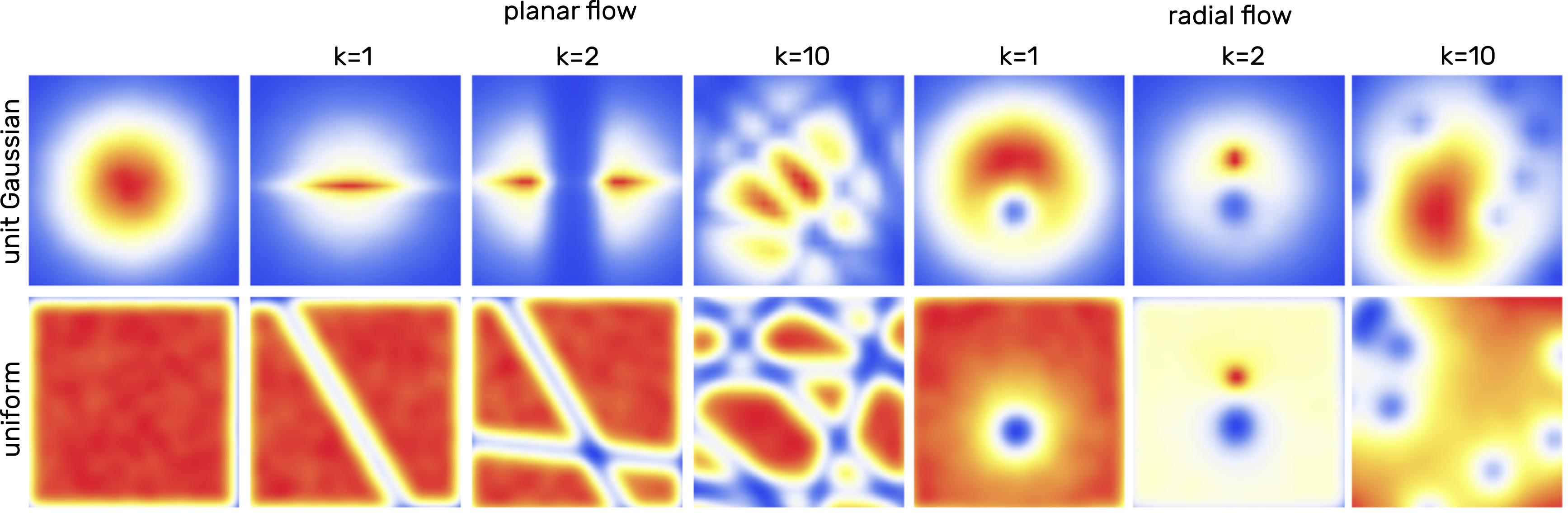] As mappings are invertible, we can express $ p(\mathbf{x} ; \theta)$ analytically from the initial density $p_0(\mathbf{z}\_0)$ and the Jacobian of the inverse transforms. .credit[Image credits: D. Rezende et al., [Variational Inference with Normalizing Flows](https://arxiv.org/pdf/1505.05770.pdf), ICML 2015.] --- class: middle ## Generative modeling of structured high-dimensional data .center[**High-dimensional data** $\mathbf{x} \in \mathbb{R}^D$ such as natural images or speech signals exhibit some form of **regularity**, preventing their dimensions from varying independently.] <br> .center.width-90[] .center[From a **generative perspective**, this regularity suggests that there exists a smaller dimensional **latent variable** $\mathbf{z} \in \mathbb{R}^K$ that generated $\mathbf{x} \in \mathbb{R}^D$, $K \ll D$.] .credit[Picture credits: <a href="https://fr.freepik.com/photos-gratuite/heureuse-fille-aux-cheveux-boucles-fait-signe-pouce-air-demontre-son-soutien-son-respect-quelqu-sourit-agreablement-atteint-objectif-souhaitable-porte-t-shirt-blanc-isole-mur-jaune_11932454.htm#query=black%20woman%20face&position=2&from_view=search">wayhomestudio</a> on Freepik. ] --- class: middle ## Latent-variable-based generative modeling .center.width-90[] - The model distribution is defined as a marginal distribution. - GANs and VAEs are two examples of latent-variable-based DGM, but $p(\mathbf{x} | \mathbf{z} ; \theta)$ is only defined analytically for VAEs. - Today we will focus on VAEs. - Diffusion models (the SOTA in 2024) can be seen as Markovian hierarchical VAEs. --- - A trained VAE can be used for **generation**, **transformation**, and **downstream tasks**. - Ideally, the learned representation should be **disentangled** .small[(Higgins et al., 2018)], i.e., somehow easy to relate to independent and interpretable high-level characteristics of the data. .center.width-85[] .alert[Supervised learning from disentangled representations has been found to be more sample-efficient, more robust, and better in terms of generalization .small[(van Steenkiste et al., 2019)].] .credit[ .small-vspace[ ] I. Higgins et al., Towards a definition of disentangled representations. arXiv preprint arXiv:1812.02230, 2018. <br> S. Sadok et al., Learning and controlling the source-filter representation of speech with a variational autoencoder, Speech Communication, 2023. <br> S. van Steenkiste et al., Are disentangled representations helpful for abstract visual reasoning?, NeurIPS, 2019. ] --- class: middle, center # Example applications --- class: middle ## VAE for face generation .center.width-70[] .credit[A. Vahdat and J. Kautz [NVAE: A Deep Hierarchical Variational Autoencoder](https://arxiv.org/pdf/2007.03898.pdf), 2020.] --- class: middle ## VAE for face manipulation in videos Transfering some attributes from the center face to the surrounding ones. .grid[ .kol-1-2[ .center[ <video controls width="400" loop autoplay muted> <source src="images/z_av.mp4" type="video/mp4"> </video> ] Lip and jaw movements are transfered. ] .kol-1-2[ .center[ <video controls width="400" loop autoplay muted> <source src="images/z_visual.mp4" type="video/mp4"> </video> ] Head and eyelid movements are transfered. ] ] .credit[S. Sadok, S. Leglaive, L. Girin, X. Alameda-Pineda, R. Séguier, [A multimodal dynamical variational autoencoder for audiovisual speech representation learning](https://hal.science/hal-04132316), Neural Networks, 2024. ] --- class: middle, center .small-nvspace[ ] Identity manipulation .center[ <video controls width="650" loop autoplay muted> <source src="images/swap_w_visual.mp4" type="video/mp4"> </video> ] --- class: middle .center[Interpolation between different identities or emotions] .grid[ .kol-1-2[ .center[ <video controls width="400" loop autoplay muted> <source src="images/identity_interpolation.mp4" type="video/mp4"> </video> ] .caption[Same emotion, different identities.] ] .kol-1-2[ .center[ <video controls width="400" loop autoplay muted> <source src="images/emotions_interpolation.mp4" type="video/mp4"> </video> ].caption[Same identity, different emotions.] ] ] --- ## VAE for sentence generation from a continuous space .center.vspace.width-50[] .caption[Interpolation in a recurrent VAE latent space] .credit[S.R. Bowman et al., [Generating Sentences from a Continuous Space](https://arxiv.org/pdf/1511.06349.pdf), 2015] --- ## VAE for automatic design of new molecules .center.vspace.width-70[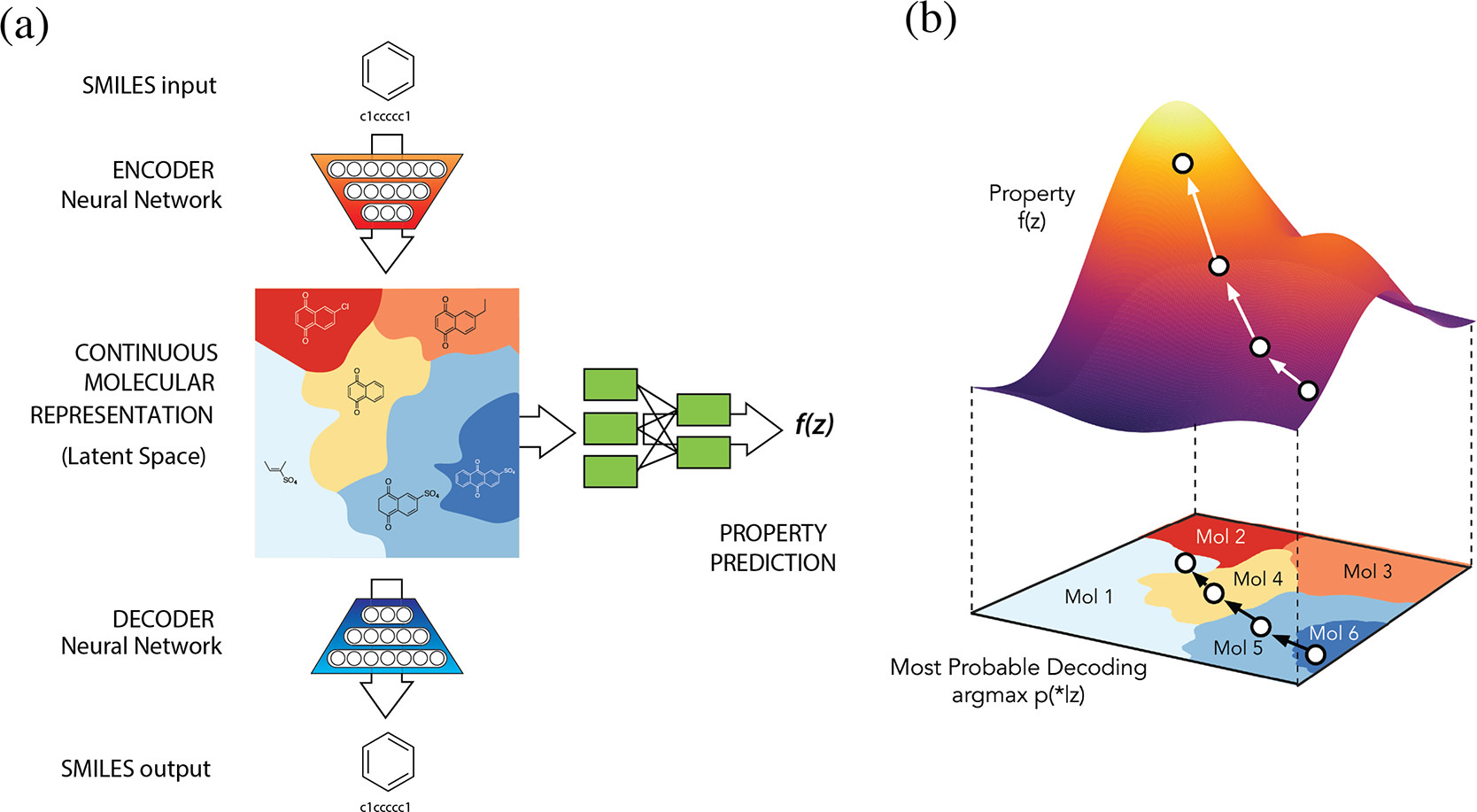] .credit[R. Gómez-Bombarelli et al., [Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules](https://pubs.acs.org/doi/full/10.1021/acscentsci.7b00572), 2018] --- ## VAE for symbolic music generation .center.vspace[ <iframe width="640" height="400" src="https://www.youtube.com/embed/G5JT16flZwM" frameborder="0" volume="0" allowfullscreen></iframe> ] .caption[Gradual blending of 2 different melodies.] .credit[A. Roberts et al., [A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music](https://arxiv.org/pdf/1803.05428.pdf), 2018] --- ## VAE for singing voice separation in music .grid[ .kol-1-3[ <img src="audio/demo_music_sep/mix_spectro.svg", width=100%> <audio controls src="audio/demo_music_sep/mix.wav"></audio> ] .kol-1-3[ <img src="audio/demo_music_sep/BRNN_VEM/vocals_spectro.svg", width=100%> <audio controls src="audio/demo_music_sep/BRNN_VEM/vocals.wav"></audio> ] .kol-1-3[ <img src="audio/demo_music_sep/BRNN_VEM/accomp_spectro.svg", width=95%> <audio controls src="audio/demo_music_sep/BRNN_VEM/accomp.wav"></audio> ] ] .credit[Simon Leglaive, X. Alameda-Pineda, L. Girin, R. Horaud, [A Recurrent Variational Autoencoder for Speech Enhancement](https://arxiv.org/pdf/1910.10942.pdf), IEEE ICASSP, 2020.] --- ## VAE for audio synthesis - Unconditional generation <table> <thead> <tr> <th style="text-align: center">Dataset</th> <th>Generation</th> </tr> </thead> <tbody> <tr> <td style="text-align: center">Darbouka (stereo)</td> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/audio/docs_darbouka_prior.mp3" controls=""></audio></td> </tr> <tr> <td style="text-align: center">VCTK (mono)</td> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/audio/hierarchical.mp3" controls=""></audio></td> </tr> </tbody> </table> .grid[ .kol-1-2[ - Strings to speech transfer <table> <thead> <tr> <th>original</th> <th>reconstructed</th> </tr> </thead> <tbody> <tr> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/eval_timbre_2/x.mp3" controls="" style="width: 200px"></audio></td> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/eval_timbre_2/y.mp3" controls="" style="width: 200px"></audio></td> </tr> </tbody> </table> ] .kol-1-2[ - Speech to strings transfer <table> <thead> <tr> <th>original</th> <th>reconstructed</th> </tr> </thead> <tbody> <tr> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/eval_timbre_1/x.mp3" controls="" style="width: 200px"></audio></td> <td><audio src="https://anonymous84654.github.io/RAVE_anonymous/eval_timbre_1/y.mp3" controls="" style="width: 200px"></audio></td> </tr> </tbody> </table> ] ] .credit[ A. Caillon, P. Esling, [RAVE: A variational autoencoder for fast and high-quality neural audio synthesis](https://arxiv.org/abs/2111.05011), arXiv, 2021. <br>https://anonymous84654.github.io/RAVE_anonymous/ ] --- class: middle ## Diffusion models for conditional image generation .center.width-100[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle, black-slide .center.width-100[] .credit[Source: https://neurips2023-ldm-tutorial.github.io/] --- class: middle, black-slide .center.width-100[] .credit[Source: https://neurips2023-ldm-tutorial.github.io/] --- class: middle, black-slide .center[ <video controls width="700" loop autoplay muted> <source src="images/teddy_bear_guitar.mp4" type="video/mp4"> </video> ].caption[Text prompt: "A teddy bear is playing the electric guitar, high definition, 4k."] .credit[ A. Blattmann et al., Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models, CVPR 2023.<br> Source: https://research.nvidia.com/labs/toronto-ai/VideoLDM/] --- class: middle The conditioning information does not need to be a text prompt. In this example it's a drawing. .center.width-100[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle ## Diffusion models for image manipulation/restoration .center.vspace.width-100[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle .center.vspace.width-100[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle .center.vspace.width-80[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle ## Diffusion models for inverse problems .center.vspace.width-80[] .credit[Source: https://cvpr2023-tutorial-diffusion-models.github.io/] --- class: middle ## Example for dereverberation <img src="audio/dereverb/p226293.png", width=100%> .grid[ .kol-1-3[ <audio controls src="audio/dereverb/p226293_reverberant.mp3"></audio> ] .kol-1-3[ <audio controls src="audio/dereverb/p226293_clean.mp3"></audio> ] .kol-1-3[ <audio controls src="audio/dereverb/p226293_buddy.mp3"></audio> ] ] .credit[Jean-Marie Lemercier et al., [Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models](https://arxiv.org/abs/2408.07472), arXiv:2408.07472, 2024.] --- class: middle ## Diffusion models for label-efficient semantic segmentation .center.width-100[] .credit[Source: https://cvpr2022-tutorial-diffusion-models.github.io/] --- class: middle .center[ # Variational autoencoders ] .credit[ D.P. Kingma and M. Welling, [Auto-Encoding Variational Bayes](https://arxiv.org/pdf/1312.6114.pdf), ICLR 2014. D.J. Rezende et. al, [ Stochastic backpropagation and approximate inference in deep generative models](https://arxiv.org/pdf/1401.4082.pdf), ICML 2014. ] --- ## Generative model Let $\mathbf{x} \in \mathbb{R}^D$ and $\mathbf{z} \in \mathbb{R}^K$ be two random vectors (typically $K \ll D$). The generative model is defined by: $$ p(\mathbf{x} ; \theta) = \int p(\mathbf{x} | \mathbf{z} ; \theta) p(\mathbf{z}) d\mathbf{z}.$$ .grid[ .kol-2-3[ - The **prior** is a standard Gaussian distribution: $$ p(\mathbf{z}) = \mathcal{N}(\mathbf{z}; \mathbf{0}, \mathbf{I}).$$ - The **likelihood** is parametrized with a **generative/decoder neural network**, e.g. $$ p(\mathbf{x} | \mathbf{z} ; \theta ) = \mathcal{N}\left( \mathbf{x}; \boldsymbol{\mu}\_\theta(\mathbf{z}), \text{diag}\left\\{ \mathbf{v}\_\theta(\mathbf{z}) \right\\} \right), $$ where $\theta$ denotes the parameters of the decoder network. ] .kol-1-3[ .right.width-80[] ] ] --- class: middle, center ## How to estimate the VAE generative model parameters? --- ## KL divergence minimization - We have defined our model distribution $\displaystyle p(\mathbf{x}; \theta) = \int p(\mathbf{x}, \mathbf{z}; \theta) d\mathbf{z} = \int p(\mathbf{x} | \mathbf{z}; \theta) p(\mathbf{z}) d\mathbf{z} $. -- count: false - We want to estimate the model parameters $\theta$ so that $p(\mathbf{x}; \theta)$ is as close as possible to the true unknown data distribution $p^\star(\mathbf{x})$. -- count: false - We take the Kullback-Leibler (KL) divergence as a measure of fit: $$D\_{\text{KL}}(p \parallel q) = \mathbb{E}\_{p}[ \ln(p) - \ln(q)] \ge 0.$$ -- count: false - We want to solve: $$ \begin{aligned} & \underset{\theta}{\min}\hspace{.1cm} D\_{\text{KL}} (p^\star(\mathbf{x}) \parallel p(\mathbf{x}; \theta)) \\\\ \Leftrightarrow \hspace{.2cm} & \underset{\theta}{\min}\hspace{.1cm} \mathbb{E}\_{p^\star(\mathbf{x})}[ \ln p^\star(\mathbf{x}) - \ln p(\mathbf{x}; \theta)] \\\\ \Leftrightarrow \hspace{.2cm} & \underset{\theta}{\max}\hspace{.1cm} \mathbb{E}\_{p^\star(\mathbf{x})}[ \ln p(\mathbf{x}; \theta)] \end{aligned} $$ -- count: false Equivalent to **maximum marginal likelihood** estimation. --- ## Empirical risk minimization - We do not have acces to the true data distribution $p^\star(\mathbf{x})$... -- count: false - ... but we have access to a dataset $\mathcal{D} = \\{\mathbf{x}\_n \in \mathbb{R}\\}\_{n=1}^N$ of independent and identically distributed (i.i.d) samples drawn from $p^\star(\mathbf{x})$: $$ \mathbf{x}\_n \overset{i.i.d}{\sim} p^\star(\mathbf{x}), \qquad \forall n \in \\{1,...,N\\}.$$ -- count: false - **Monte Carlo estimate**: The expectation is approximated by an empirical average, using i.i.d samples drawn from the true intractable distribution, $$ \mathbb{E}\_{p^\star(\mathbf{x})} [ f(\mathbf{x}; \theta) ] \approx \frac{1}{N} \sum\_{n=1}^N [f(\mathbf{x}_n; \theta)].$$ The approximation error decreases as $N$ increases (law of large numbers). -- count: false - This is a general principled called **empirical risk minimization** in statistical learning theory. --- ## Maximum likelihood estimation - To sum up, we want to minimize the KL divergence between $p^\star(\mathbf{x})$ and $p(\mathbf{x}; \theta)$ w.r.t $\theta$ (the weights and biases of the generative network), which is equivalent to solving: $$ \underset{\theta}{\max} \left\\{ \mathbb{E}\_{p^\star(\mathbf{x})}[ \ln p(\mathbf{x}; \theta)] \approx \frac{1}{N} \sum\_{n=1}^N \ln p(\mathbf{x}\_n; \theta) \right\\}.$$ -- count: false - Let's try to develop the expression of the marginal likelihood: $$ p(\mathbf{x}; \theta) = \int p(\mathbf{x}, \mathbf{z}; \theta) d\mathbf{z} = \int p(\mathbf{x} | \mathbf{z}; \theta) p(\mathbf{z}) d\mathbf{z} = \int \mathcal{N}\left(\mathbf{x}; \boldsymbol{\mu}\_\theta(\mathbf{z}), \text{diag}\left\\{ \mathbf{v}\_\theta(\mathbf{z}) \right\\} \right) \mathcal{N}(\mathbf{z}; \mathbf{0}, \mathbf{I}) d\mathbf{z}.$$ -- count: false - We cannot compute this integral analytically, because the integrand is highly non-linear in $\mathbf{z}$. -- count: false - We will resort to **variational inference** techniques, that we have already encountered in this course. --- ## Variational inference - Let the variational family $\mathcal{F}$ denote a subset of probability density functions over $\mathbf{z}$. - For any $q \in \mathcal{F}$, we have .tiny[(Neal and Hinton, 1999; Jordan et al. 1999)]: $$ \ln p(\mathbf{x}; \theta) = \mathcal{L}(\mathbf{x}; q, \theta) + D\_{\text{KL}}(q(\mathbf{z} ) \parallel p(\mathbf{z} | \mathbf{x}; \theta)),$$ where $\mathcal{L}(\mathbf{x}; q, \theta)$ is called the **evidence lower bound** (ELBO), and it is defined by $$ \mathcal{L}(\mathbf{x}; q, \theta) = \mathbb{E}\_{q(\mathbf{z})} [\ln p(\mathbf{x}, \mathbf{z}; \theta) - \ln q(\mathbf{z} )]. $$ .credit[ R.M. Neal and G.E. Hinton, ["A view of the EM algorithm that justifies incremental, sparse, and other variants"](http://www.cs.toronto.edu/~radford/ftp/emk.pdf), in M. I. Jordan (Ed.), .italic[Learning in graphical models], Cambridge, MA: MIT Press, 1999. <br> M.I. Jordan et al., ["An introduction to variational methods for graphical models"](https://people.eecs.berkeley.edu/~jordan/papers/variational-intro.pdf), Machine learning, 1999.] -- count: false .left-column.center[ <hr style="border:1px solid black" width="70%"> </hr> .bold[Problem #1] $$ \underset{\theta}{\max}\, \mathcal{L}(\mathbf{x}; q, \theta),$$ where $\mathcal{L}(\mathbf{x}; q, \theta) \le \ln p(\mathbf{x}; \theta)$ ] .right-column.center[ <hr style="border:1px solid black" width="70%"> </hr> .bold[Problem #2] $$ \underset{q \in \mathcal{F}}{\max}\, \mathcal{L}(\mathbf{x}; q, \theta) $$ $$ \Leftrightarrow \underset{q \in \mathcal{F}}{\min}\, D\_{\text{KL}}(q(\mathbf{z}) \parallel p(\mathbf{z} | \mathbf{x}; \theta))$$ ] .reset-column[ ] --- class: middle ## Variational family and inference model - To fully define the ELBO objective function, we need to specify the **variational family** $\mathcal{F}$. - In the original VAE, $\mathcal{F}$ is defined as the set of Gaussian pdfs of the form $$ q(\mathbf{z} | \mathbf{x}; \phi) = \mathcal{N}\left( \mathbf{z}; \boldsymbol{\mu}\_\phi(\mathbf{x}), \text{diag}\left\\{ \mathbf{v}\_\phi(\mathbf{x}) \right\\} \right),$$ where the mean and variance vectors are provided by an **encoder** neural network. .vspace.center.width-30[] - $q(\mathbf{z} | \mathbf{x}; \phi)$ is called the **inference model** and it approximates the intractable posterior $p(\mathbf{z} | \mathbf{x}; \theta)$. --- class: middle - The variational family $\mathcal{F}$ is fully parametrized by the parameters $\phi$ of the encoder neural network. - Instead of defining the ELBO $\mathcal{L}(\mathbf{x}; q, \theta)$ over the space of pdfs $q \in \mathcal{F}$ we can define it as a parametric function of $\phi$: $$ \mathcal{L}(\mathbf{x}; \phi, \theta) = \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x}, \mathbf{z}; \theta) - \ln q(\mathbf{z} | \mathbf{x}; \phi)]. $$ - The optimization of the ELBO over $q \in \mathcal{F}$ thus corresponds to the optimization of the ELBO over the parameters $\phi$. --- ## ELBO The ELBO is now fully defined: $$ \begin{aligned} \mathcal{L}(\mathbf{x}; \phi, \theta) &= \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x}, \mathbf{z}; \theta) - \ln q(\mathbf{z} | \mathbf{x}; \phi)] \\\\ &= \underbrace{\mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)]}\_{\text{reconstruction accuracy}} - \underbrace{D\_{\text{KL}}(q(\mathbf{z} | \mathbf{x}; \phi) \parallel p(\mathbf{z}))}\_{\text{regularization}}. \end{aligned} $$ - prior: $ \hspace{2cm} p(\mathbf{z}) = \mathcal{N}(\mathbf{z}; \mathbf{0}, \mathbf{I})$ - likelihood model: $ \hspace{.45cm} p(\mathbf{x} | \mathbf{z} ; \theta ) = \mathcal{N}\left( \mathbf{x}; \boldsymbol{\mu}\_\theta(\mathbf{z}), \text{diag}\left\\{ \mathbf{v}\_\theta(\mathbf{z}) \right\\} \right)$ - inference model: $ \hspace{.42cm} q(\mathbf{z} | \mathbf{x}; \phi) = \mathcal{N}\left( \mathbf{z}; \boldsymbol{\mu}\_\phi(\mathbf{x}), \text{diag}\left\\{ \mathbf{v}\_\phi(\mathbf{x}) \right\\} \right)$ --- class: middle $$ \mathcal{L}(\mathbf{x}; \phi, \theta) = \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)] - D\_{\text{KL}}(q(\mathbf{z} | \mathbf{x}; \phi) \parallel p(\mathbf{z})).$$ <hr> .vspace[ ] Let's first focus on the second term of the ELBO which is called the **regularization term** because it constrains the inference model to be not too far from the prior. .vspace[ ] $$ \begin{aligned} D\_{\text{KL}}(q(\mathbf{z} | \mathbf{x}; \phi) \parallel p(\mathbf{z})) &= \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \left[ \ln q(\mathbf{z} | \mathbf{x}; \phi) - \ln p(\mathbf{z}) \right] \\\\ &= \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \left[ \ln \mathcal{N}\left( \mathbf{z}; \boldsymbol{\mu}\_\phi(\mathbf{x}), \text{diag}\left\\{ \mathbf{v}\_\phi(\mathbf{x}) \right\\} \right) - \ln \mathcal{N}\left( \mathbf{z}; \mathbf{0}, \mathbf{I} \right) \right] \\\\ &= \sum\_{k=1}^K \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \Big[ \ln \mathcal{N}\left( z\_k; \mu\_{k,\phi}(\mathbf{x}), v\_{k,\phi}(\mathbf{x}) \right) - \ln \mathcal{N}\left( z\_k; 0, 1 \right)\Big] \\\\ &= ... \\\\ &= - \frac{1}{2} \sum\_{k=1}^K \Big[ \ln v\_{k,\phi}(\mathbf{x}) - \mu\_{k,\phi}^2(\mathbf{x}) - v\_{k,\phi}(\mathbf{x}) \Big] + cst(\phi) \end{aligned} $$ --- class: middle $$ \mathcal{L}(\mathbf{x}; \phi, \theta) = \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)] - D\_{\text{KL}}(q(\mathbf{z} | \mathbf{x}; \phi) \parallel p(\mathbf{z})).$$ <hr> .vspace[ ] Let's now focus on the second term, which is called the **reconstruction accuracy term**. $$ \begin{aligned} \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)] &= \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \Big[ \ln \mathcal{N}\left( \mathbf{x}; \boldsymbol{\mu}\_\theta(\mathbf{z}), \text{diag}\left\\{ \mathbf{v}\_\theta(\mathbf{z}) \right\\} \right) \Big] \\\\ &= \sum\_{d=1}^D \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \Big[ \ln \mathcal{N}\left( x\_d; \mu\_{d,\theta}(\mathbf{z}), v\_{d,\theta}(\mathbf{z}) \right) \Big]\\\\ &= -\frac{1}{2} \sum\_{d=1}^D \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \Bigg[ \ln \big(2 \pi\, v\_{d,\theta}(\mathbf{z}) \big) + \frac{\big( x\_d - \mu\_{d,\theta}(\mathbf{z})\big)^2}{v\_{d,\theta}(\mathbf{z})} \Bigg] \end{aligned} $$ A common approach consist in choosing $ v\_{d,\theta}(\mathbf{z}) = 1 $ for all $d \in \\{1,...,D\\}$, such that the reconstruction accuracy term involves the **mean squared error** between the data $\mathbf{x}$ and the mean vector $\boldsymbol{\mu}\_\theta(\mathbf{z})$ provided by the decoder network. --- ## Reconstruction accuracy term $$ \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)] = -\frac{1}{2} \sum\_{d=1}^D \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} \Bigg[ \ln \big(2 \pi\, v\_{d,\theta}(\mathbf{z}) \big) + \frac{\big( x\_d - \mu\_{d,\theta}(\mathbf{z})\big)^2}{v\_{d,\theta}(\mathbf{z})} \Bigg]. $$ -- count: false - **.bold[Problem 1]** - The expectation cannot be computed analytically. -- count: false - **.bold[Solution 1]** - Approximate it with a Monte Carlo estimate: $$ \mathbb{E}\_{q(\mathbf{z} | \mathbf{x}; \phi)} [\ln p(\mathbf{x} | \mathbf{z}; \theta)] \approx -\frac{1}{2 R} \sum\_{d=1}^D \sum\_{r=1}^R \Bigg[ \ln \big(2 \pi\, v\_{d,\theta}(\mathbf{z}\_r) \big) + \frac{\big( x\_d - \mu\_{d,\theta}(\mathbf{z}\_r)\big)^2}{v\_{d,\theta}(\mathbf{z}\_r)} \Bigg], $$ where $\\{\mathbf{z}\_r\\}\_{r=1}^{R}$ are i.i.d samples drawn from $q(\mathbf{z} | \mathbf{x}; \phi)$. Note that in practice, we choose $R=1$. -- count: false - **.bold[Problem 2]** - This sampling operation is not differentiable w.r.t. $\phi$. -- count: false - **.bold[Solution 2]** - Use the so-called .bold[reparametrization trick]. --- ## Reparametrization trick - The reparameterization trick consists in rewritting the sampling operation of $\mathbf{z}\_r$ from $ q(\mathbf{z} | \mathbf{x}; \phi)$ as a invertible transformation of another random sample $\boldsymbol{\epsilon}\_r$, drawn from a distribution $p(\boldsymbol{\epsilon})$ which is independent of $\mathbf{x}$ and $\phi$. -- count: false - In our case, we have $q(\mathbf{z} | \mathbf{x}; \phi) = \mathcal{N}\left( \boldsymbol{\mu}\_\phi(\mathbf{x}), \text{diag}\left\\{ \mathbf{v}\_\phi(\mathbf{x}) \right\\} \right)$. -- count: false - A simple reparametrization is given by: $$ \mathbf{z}\_r = \boldsymbol{\mu}\_\phi(\mathbf{x}) + \text{diag}\left\\{ \mathbf{v}\_\phi(\mathbf{x}) \right\\}^{1/2} \boldsymbol{\epsilon}\_r, $$ where $\boldsymbol{\epsilon}\_r$ is drawn from $\mathcal{N}(\mathbf{0}, \mathbf{I})$. --- ## Finally, the full ELBO - Putting all together, we end-up with the following expression of the ELBO: $$ \begin{aligned} \mathcal{L}(\mathbf{x}; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big(v\_{d,\theta}(\tilde{\mathbf{z}}) \big) + \frac{\big( x\_d - \mu\_{d,\theta}(\tilde{\mathbf{z}})\big)^2}{v\_{d,\theta}(\tilde{\mathbf{z}})} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln v\_{k,\phi}(\mathbf{x}) - \mu\_{k,\phi}^2(\mathbf{x}) - v\_{k,\phi}(\mathbf{x}) \Big] + cst(\phi, \theta), \end{aligned} $$ where $\tilde{\mathbf{z}}$ is drawn from $q(\mathbf{z} | \mathbf{x}; \phi)$ using the .bold[reparametrization trick]. -- count: false - This objective function is differentiable with respect to $\phi$ and $\theta$. It can be optimized with gradient-ascent-based techniques, where gradients are computed by backpropagation. -- count: false - Do not forget that we actually maximize a sample average over our training dataset: $$ \underset{\phi, \, \theta}{\max} \left\\{ \mathbb{E}\_{p^\star(\mathbf{x})}[ \mathcal{L}(\mathbf{x}; \phi, \theta)] \approx \frac{1}{N} \sum\limits\_{n=1}^N \mathcal{L}(\mathbf{x}\_n; \phi, \theta) \right\\}.$$ --- ## Training procedure ### Step 0: Do the math $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big(v\_{d,\theta}(\tilde{\mathbf{z}}\_n) \big) + \frac{\big( { x\_{n,d}} - \mu\_{d,\theta}(\tilde{\mathbf{z}}\_n)\big)^2}{v\_{d,\theta}(\tilde{\mathbf{z}}\_n)} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln v\_{k,\phi}({\mathbf{x}\_n}) - \mu\_{k,\phi}^2({\mathbf{x}\_n}) - v\_{k,\phi}({\mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ --- ## Training procedure ### Step 1: Pick an example in the dataset $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big(v\_{d,\theta}(\tilde{\mathbf{z}}\_n) \big) + \frac{\big( {\color{brown} x\_{n,d}} - \mu\_{d,\theta}(\tilde{\mathbf{z}}\_n)\big)^2}{v\_{d,\theta}(\tilde{\mathbf{z}}\_n)} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln v\_{k,\phi}({\color{brown} \mathbf{x}\_n}) - \mu\_{k,\phi}^2({\color{brown} \mathbf{x}\_n}) - v\_{k,\phi}({\color{brown} \mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ .center.width-80[] --- ## Training procedure ### Step 2: Map through the encoder $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big(v\_{d,\theta}(\tilde{\mathbf{z}}\_n) \big) + \frac{\big( {\color{green} x\_{n,d}} - \mu\_{d,\theta}(\tilde{\mathbf{z}}\_n)\big)^2}{v\_{d,\theta}(\tilde{\mathbf{z}}\_n)} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln {\color{brown} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) - {\color{brown} \mu\_{k,\phi}^2 } ({\color{green} \mathbf{x}\_n}) - {\color{brown} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ .center.width-80[] --- ## Training procedure ### Step 3: Sample $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big(v\_{d,\theta}({\color{brown} \tilde{\mathbf{z}}\_n }) \big) + \frac{\big( {\color{green} x\_{n,d}} - \mu\_{d,\theta}({\color{brown} \tilde{\mathbf{z}}\_n })\big)^2}{v\_{d,\theta}({\color{brown} \tilde{\mathbf{z}}\_n })} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) - {\color{green} \mu\_{k,\phi}^2} ({\color{green} \mathbf{x}\_n}) - {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ .center.width-80[] --- ## Training procedure ### Step 4: Map through the decoder $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big({\color{brown} v\_{d,\theta}} ({\color{green} \tilde{\mathbf{z}}\_n }) \big) + \frac{\big( {\color{green} x\_{n,d}} - {\color{brown}\mu\_{d,\theta}} ({\color{green} \tilde{\mathbf{z}}\_n })\big)^2}{{\color{brown} v\_{d,\theta} } ({\color{green} \tilde{\mathbf{z}}\_n })} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) - {\color{green} \mu\_{k,\phi}^2} ({\color{green} \mathbf{x}\_n}) - {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ .center.width-80[] --- ## Training procedure ### Step 5: Backpropagate and gradient step $$ \begin{aligned} \mathcal{L}(\mathbf{x}\_n; \phi, \theta) =\,\,&-\frac{1}{2} \sum\_{d=1}^D \Bigg[ \ln \big({\color{green} v\_{d,\theta}} ({\color{green} \tilde{\mathbf{z}}\_n }) \big) + \frac{\big( {\color{green} x\_{n,d}} - {\color{green}\mu\_{d,\theta}} ({\color{green} \tilde{\mathbf{z}}\_n })\big)^2}{{\color{green} v\_{d,\theta} } ({\color{green} \tilde{\mathbf{z}}\_n })} \Bigg] \\\\ \,\,& + \frac{1}{2} \sum\_{k=1}^K \Big[ \ln {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) - {\color{green} \mu\_{k,\phi}^2} ({\color{green} \mathbf{x}\_n}) - {\color{green} v\_{k,\phi}} ({\color{green} \mathbf{x}\_n}) \Big] + cst(\phi, \theta), \end{aligned} $$ .center.width-80[] .footnote[You can also average over mini batches before doing the backpropagation.] --- ## At test time (after training) .center.width-100[] - Note that the encoder was only introduced in order to estimate the parameters of the decoder. - We do not need the encoder for generating new samples. - But it is useful if we need to do inference. --- class: center, middle count: false # Jupyter Notebook --- ## Generated MNIST samples .vspace.center.width-40[] .caption[VAE with $K=16$] --- class: middle, center .center[<img src="./images/walking_latent_space.png" style="width: 450px;" />] .tiny[Linearly spaced coordinates on the unit square are transformed through the inverse cumulative distribution function of the Gaussian to produce values of the latent variables which are then mapped through the decoder network.] --- class: center, middle # Diffusion models --- .center.width-80[] .credit[ Ho et al., [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239), NeurIPS, 2020 Image credits: NeurIPS 2023 Tutorial [Latent Diffusion Models: Is the Generative AI Revolution Happening in Latent Space?](https://neurips2023-ldm-tutorial.github.io/) by K. Kreis, R. Gao, and A. Vahdat. ] --- class: middle A **diffusion model** can be seen as a Markovian hierarchical VAE: - We have a hierarchy of latent variables involved in the generative model; - Each latent variable in this hierarchy has the same dimension equal to the data dimension $D$; - The encoder is not learned, it is fixed following a Markovian model with parameters (noise schedule) chosen such that the distribution of the latent variable at the final step of the forward diffusion process is a standard Gaussian. - The decoder also has a Markovian structure, with a transition distribution involving a neural network learned via ELBO maximization. .alert-g[For a tutorial on the connections between VAEs and diffusion models, see [Understanding Diffusion Models: A Unified Perspective](https://arxiv.org/pdf/2208.11970.pdf) by Calvin Luo (Google Research, Brain Team), 2022.]